Breadth-first Search
Application Description
This benchmark computes the shortest path from a source node to all nodes in a directed, unweighted graph.
Application Description
We have 2 distributed implementations of BFS: a push-style and a pull-style. Both are bulk-synchronous parallel (BSP) implementations: execution proceeds in rounds, and synchronization of data among hosts occurs between rounds.
The push-style version checks a node to see if its distance has changed since the last round. If it has, it will update its neighbor's distances using its new distance. The pull-style version goes over all nodes: all nodes check their in-neighbors, and if a neighbor has a distance that results in a new shortest path distance, then a node updates itself with its neighbors' data. Execution of both versions continues until there are no more nodes that are updated in a round.
Psuedocode for the computation step of the 2 implementations follows below:
| 1 2 3 4 5 6 7 | for (node n in graph) { if (n.distance != n.old_distance) { for (neighbor a of node n) { a.distance = min(n.distance + 1, a.distance) } } } |
Figure 1: Pseudocode for BFS Push computation
| 1 2 3 4 5 6 7 8 | for (node n in graph) { for (in-neighbor a of node n) { if (a.distance + 1 < n.distance) { n.distance = a.distance + 1 } } } } |
Figure 2: Pseudocode for BFS Pull computation
Synchronization of the distance variable occurs between BSP rounds. A node will take the minimum distance value of all proxies that exist in the system for that node.
Performance
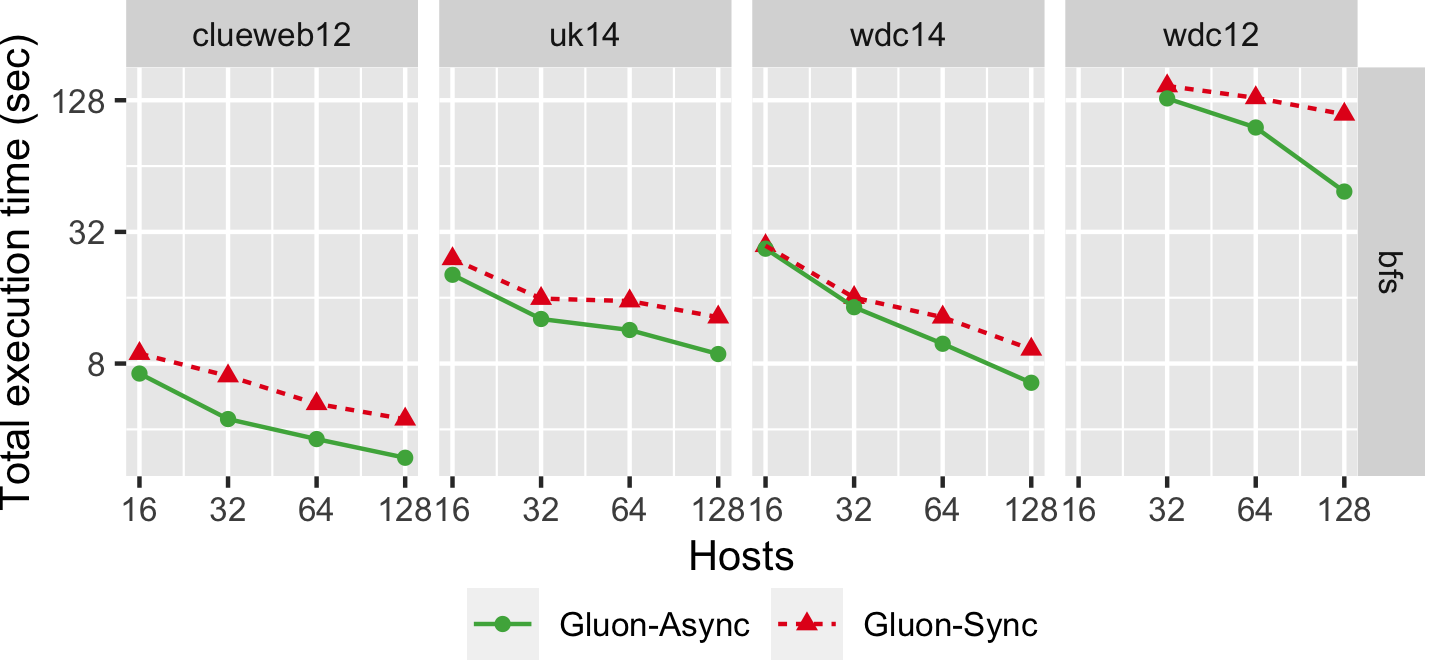
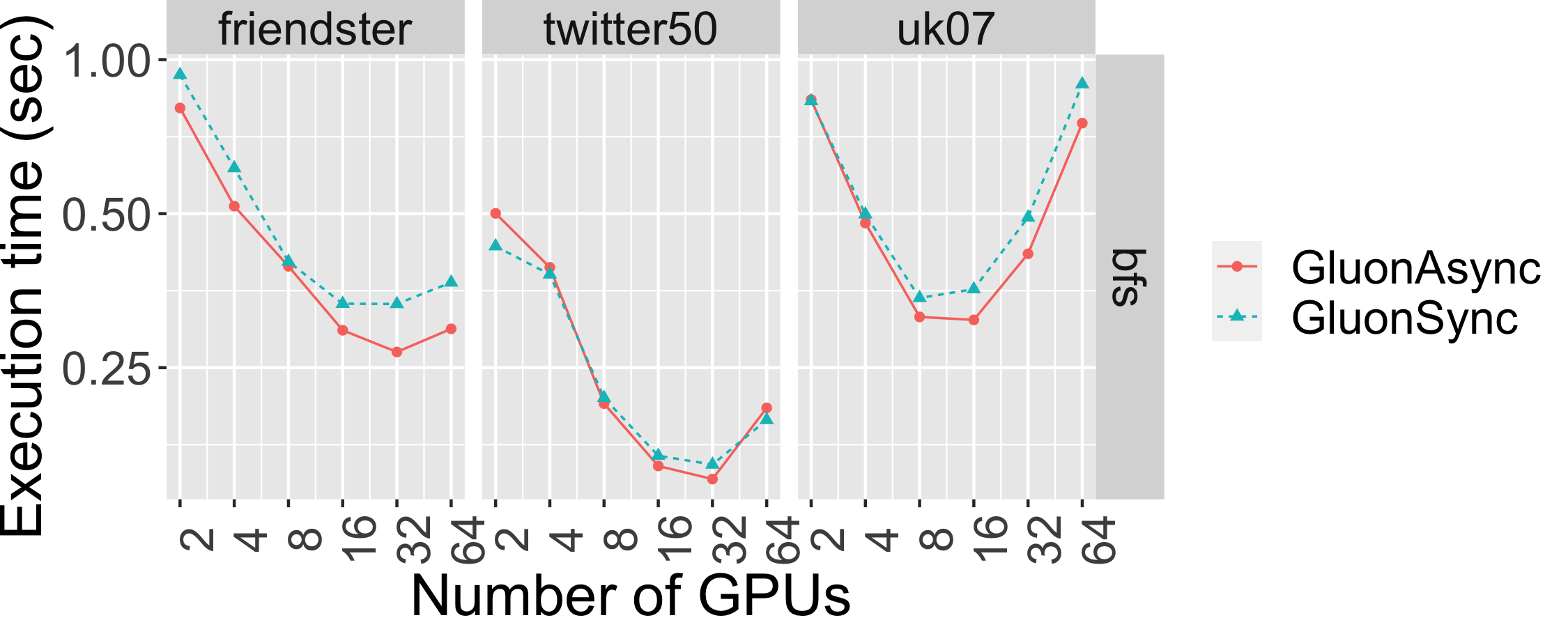
The graph below shows the strong scaling of bfs-push using both Bulk Synchronous Parallel (Gluon-Sync) and Bulk-Asynchronous Parallel (Gluon-Async) execution models which use a Gluon communication substrate. The experiments were conducted on Stampede Cluster (Stampede2), which is connected through Intel Omni-Path Architecture (peak bandwidth of 100Gbps). Each node has 2 Intel Xeon Platinum 8160 “Skylake” CPUs with 24 cores per CPU and 192GB DDR4 RAM. We use up to 128 CPU machines, each with 48 threads. We run on 4 graphs: clueweb12, uk14, wdc14, and wdc12. Most are real-world web-crawls: the web data commons hyperlink graph. wdc12, is the largest publicly available dataset. wdc14, clueweb12, and uk14 are all other large web-crawls.