Connected Components
Application Description
A connected component of an undirected graph is a subgraph in which there is a path between any two nodes. A node with no edges is itself a connected component.
Application Description
Our distributed implementation of connected components is a bulk-synchronous parallel (BSP) label propagation algorithm: all nodes are initialized to a label of their own vertex ID, and in each round, the current ID is propagated to its neighbors. Nodes will overwrite their labels with the smallest vertex ID that it receives. This propagation continues until no node label changes in a round. We have a push variant and a pull variant of the algorithm.
The push-style version has a node push out its label only if it has changed from the label in the last round. The pull-style version has all nodes check their neighbors and take the smallest label from itself and its neighbors.
Psuedocode for the computation step of the 2 implementations follows below:
| 1 2 3 4 5 6 7 | for (node n in graph) { if (n.label != n.old_label) { for (neighbor a of node n) { a.label = min(n.label, a.label) } } } |
Figure 1: Pseudocode for CC Push computation
| 1 2 3 4 5 6 7 8 | for (node n in graph) { for (neighbor a of node n) { if (a.label < n.label) { n.label = a.label } } } } |
Figure 2: Pseudocode for CC Pull computation
Synchronization of the label variable occurs between BSP rounds. A node will take the minimum label value of all proxies that exist in the system for that node.
Performance
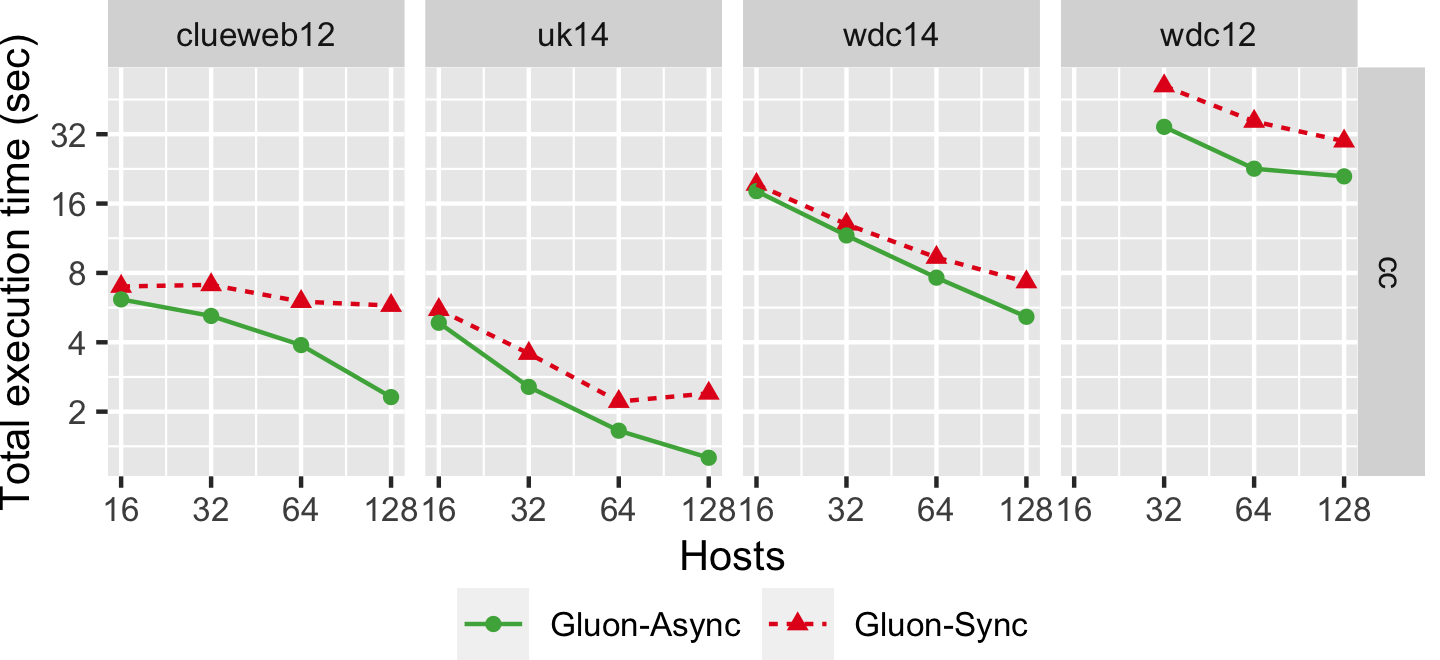
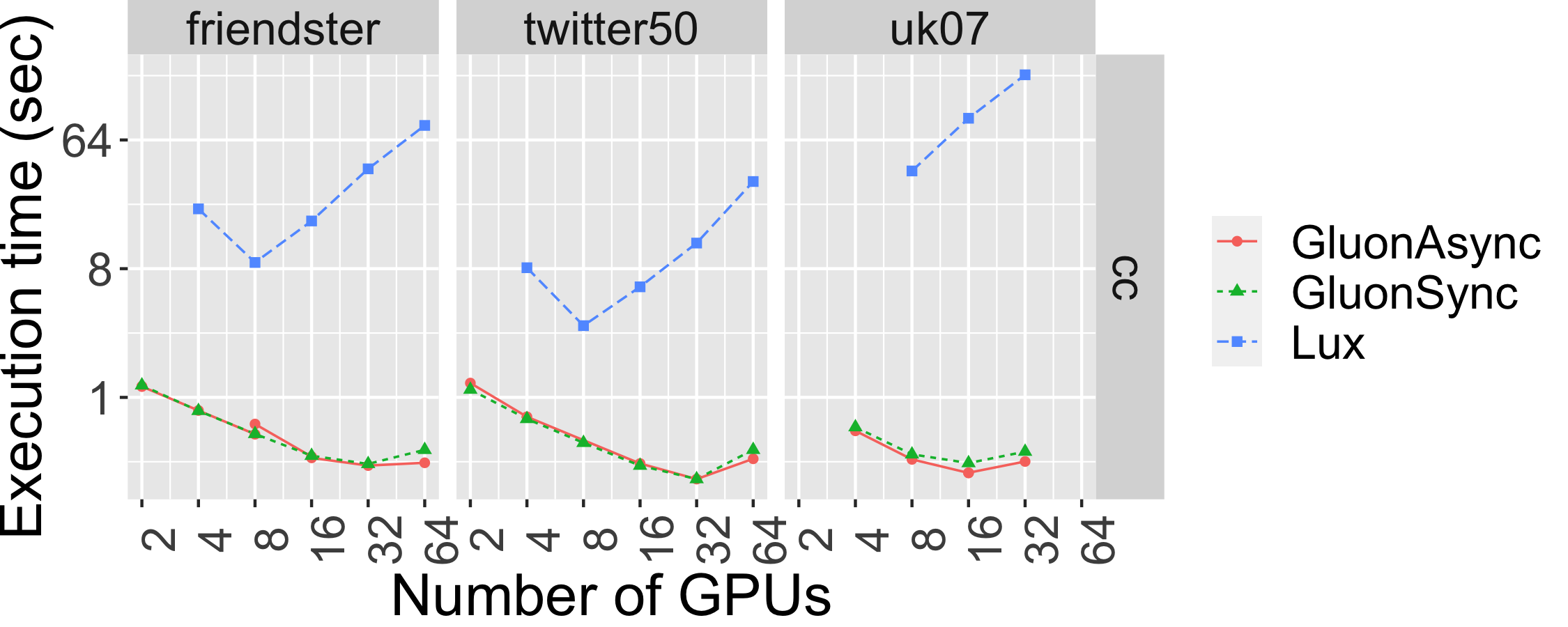
The graph below shows the strong scaling of cc-push using both Bulk Synchronous Parallel (Gluon-Sync) and Bulk-Asynchronous Parallel (Gluon-Async) execution models which use a Gluon communication substrate. The experiments were conducted on Stampede Cluster (Stampede2), which is connected through Intel Omni-Path Architecture (peak bandwidth of 100Gbps). Each node has 2 Intel Xeon Platinum 8160 “Skylake” CPUs with 24 cores per CPU and 192GB DDR4 RAM. We use up to 128 CPU machines, each with 48 threads. We run on 4 graphs: clueweb12, uk14, wdc14, and wdc12. Most are real-world web-crawls: the web data commons hyperlink graph. wdc12, is the largest publicly available dataset. wdc14, clueweb12, and uk14 are all other large web-crawls.