Triangle Counting
Problem Description
This benchmark counts the number of triangles in a given undirected graph. It uses a new graph partitioning scheme that avoids communication during triangle counting.
Algorithm
To count the number of triangles in a distributed platform, we use a a novel application-agnostic graph partitioning strategy. The strategy eliminates almost all communication for distributed triangle counting. Each machine in a distributed cluster performs triangle counting independently in its own partition without communicating with other hosts. In the end, the total triangle count is obtained by aggregating the local triangle counts from all machines. More details about the partitioning strategy and the distributed triangle counting can be found in [1].
[1] Loc Hoang, Vishwesh Jatala, Xuhao Chen, Udit Agarwal, Roshan Dathathri, Gurbinder Gill, and Keshav Pingali, DistTC: High Performance Distributed Triangle Counting. In 2019 IEEE High Performance Extreme Computing Conference, HPEC 2019. IEEE, 2019.
Performance
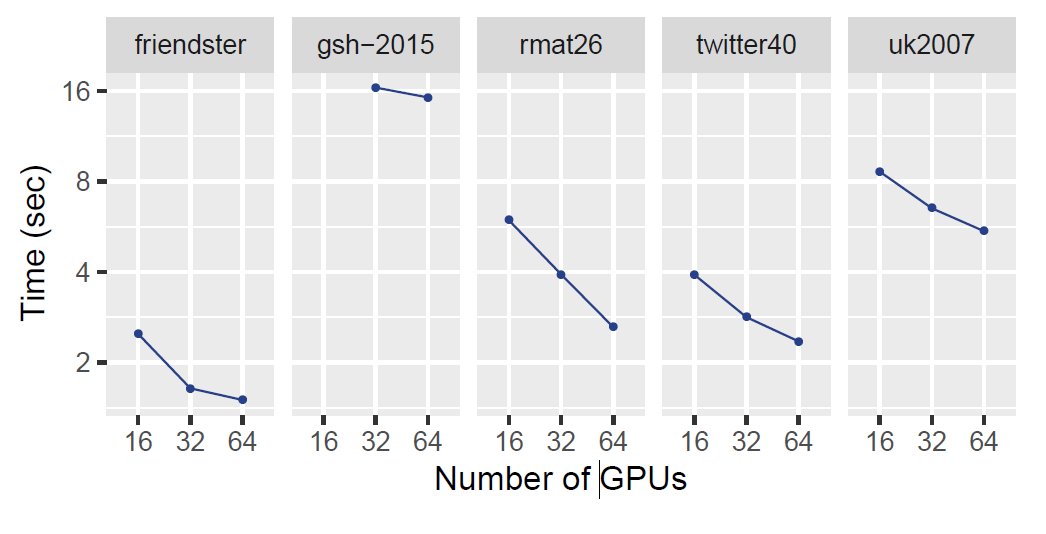
The graph below shows the performance of distributed triangle counting (DistTC) on Bridges cluster at the Pittsburgh Supercomputing Center. We used up to 64 NVIDIA Tesla P100 GPUs located on 32 distributed machines with 128GB DRAM each. Each P100 GPU has 16GB of memory. Each node in the cluster has 2 Intel Broadwell E5-2683 v4 CPUs with 16 cores per CPU. The nodes in the cluster are connected through the Intel Omni-Path Architecture. We run on five graphs (friendster, gsh-2015, rmat26, twitter40, and uk2007) on up to 64 GPUs (32 nodes on Bridges). The below table show the properties of the input graph. rmat26 is a synthetic graph generated by an RMAT generator; twitter40, friendster, uk-2007, gsh-2015, and clueweb12 are web crawls. Input graphs are symmetric, have no self-loops, and have no duplicated edges.Input Properties
| Graph | Vertices | Undirected Edges | No. of Triangles |
|---|---|---|---|
| friendster | 65,608,366 | 1,806,067,135 | 4,173,724,142 |
| gsh-2015 | 988,490,691 | 25,690,705,118 | 910,140,734,636 |
| rmat26 | 67,108,864 | 1,065,788,093 | 43,646,321,254 |
| twitter40 | 41,652,230 | 1,202,513,046 | 34,824,916,864 |
| uk2007 | 105,896,435 | 3,301,876,564 | 286,701,284,103 |