PageRank
Application Description
PageRank is a key technique in web mining to rank the importance of web pages. In PageRank, each web page is assigned a numerical weight to begin with, and the algorithm tries to estimate the importance of the web page relative to other web pages in the hyperlinked set of pages. The key assumption is that more important web pages are likely to receive more links from other websites. More details about the problem and different solutions can be found in [1, 2].
[1]
https://en.wikipedia.org/wiki/PageRank
[2] Whang et al.
Scalable Data-driven PageRank: Algorithms, System Issues, and Lessons Learned.
European Conference on Parallel Processing, 2015.
This benchmark computes the PageRank of the nodes for a given input graph using both a push-style and a pull-style residual-based algorithm. Both the algorithms take as input a graph, and some constant parameters that are used in the computation. The algorithmic parameters are the following:
- ALPHA: ALPHA represents the damping factor, which is the probability that a web surfer will continue browsing by clicking on the linked pages. The damping factor is generally set to 0.85 in the literature.
- TOLERANCE: It represents a bound on the error in the computation.
- MAX_ITER: The number of iterations to repeat the PageRank computation.
The base implementation of the push and pull style PageRanks that are implemented as a distributed benchmark are both residual PageRank. More details on residual style PageRank can be found in the Lonestar webpage for PageRank. The implementation is bulk-synchronous parallel (BSP).
Synchronization across machines is required for the residual variable on the nodes. This field is synchronized through a sum reduction. All proxies get the same value and adjust their ranks locally.
Performance
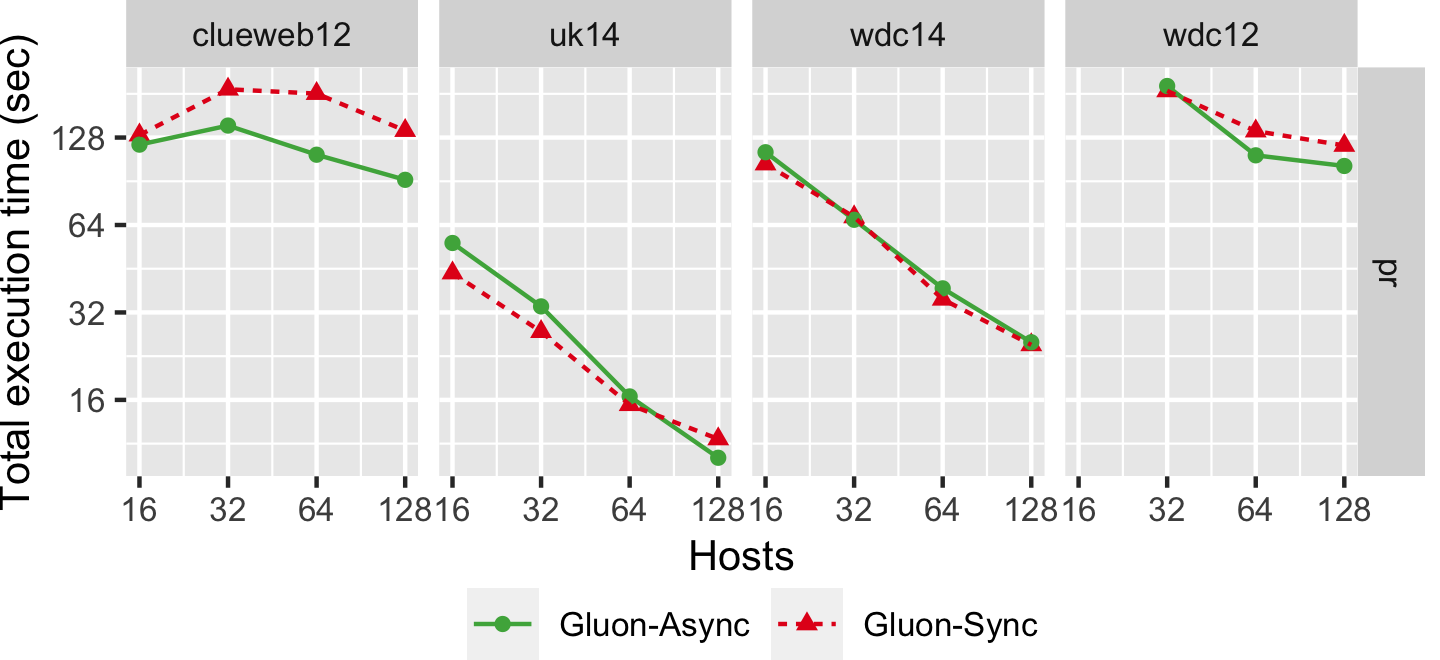
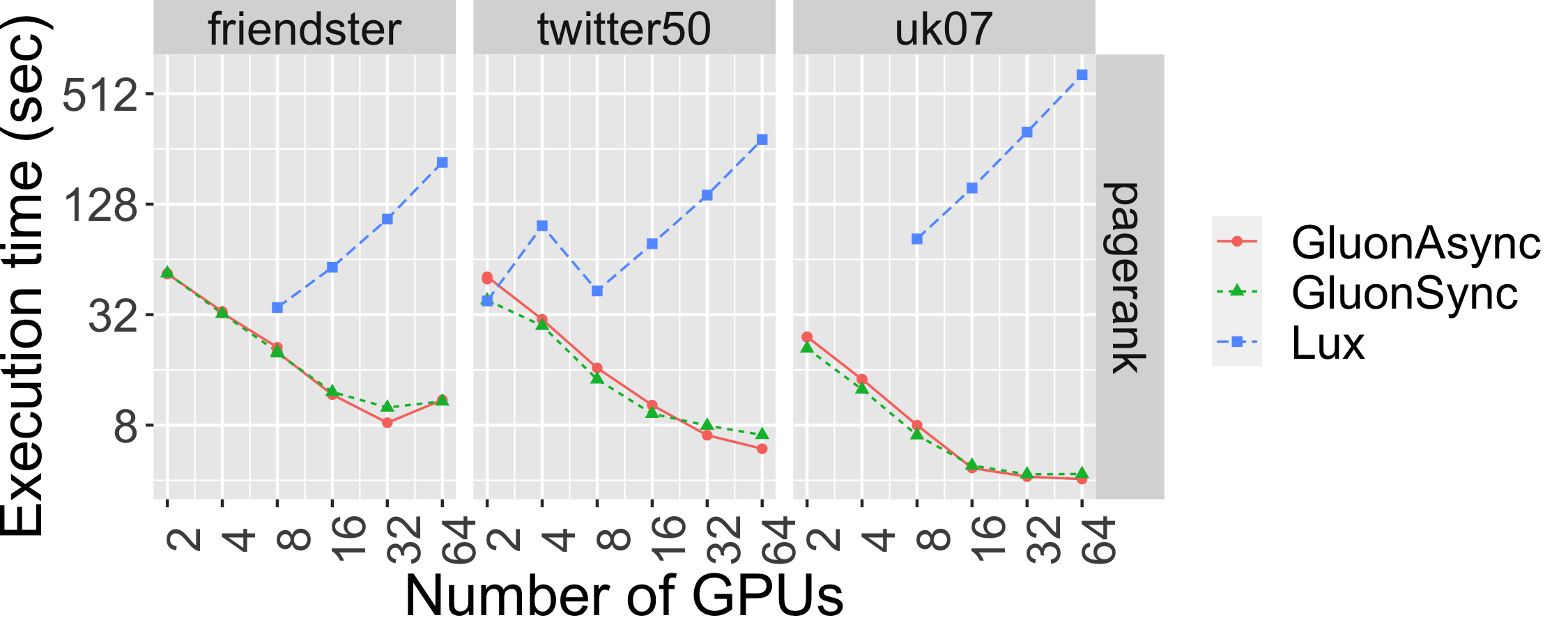
The graph below shows the strong scaling of pr-pull using both Bulk Synchronous Parallel (Gluon-Sync) and Bulk-Asynchronous Parallel (Gluon-Async) execution models which use a Gluon communication substrate. The experiments were conducted on Stampede Cluster (Stampede2), which is connected through Intel Omni-Path Architecture (peak bandwidth of 100Gbps). Each node has 2 Intel Xeon Platinum 8160 “Skylake” CPUs with 24 cores per CPU and 192GB DDR4 RAM. We use up to 128 CPU machines, each with 48 threads. We run on 4 graphs: clueweb12, uk14, wdc14, and wdc12. Most are real-world web-crawls: the web data commons hyperlink graph. wdc12, is the largest publicly available dataset. wdc14, clueweb12, and uk14 are all other large web-crawls.